(Computer-)Scientific Abstracts, As Analyzed by a Confused Undergrad
No, I didn’t just do this for fun1
I recently decided I wanted try presenting my work at an academic conference,2 so I had to write and submit an abstract for my proposed presentation. The problem, of course, was that I had no idea how to write a scientific abstract, which was a bit of a problem.3 Most of the advice I received and could find online was too vague for my taste,4 so I decided to take matters into my own hands and deconstruct some abstracts to see how those authors did it. And I’m really glad I did, because it was very enlightening.
I looked at some abstracts from a few different disciplines, which I’ll be showing in this article, but I should probably mention that the first thing I did during my writing process was search up terms that sounded like they might be relevant to my research along with the suffix “academic paper”. I didn’t really do a proper lit review while I was actually carrying out the research project, since I had no idea how to do one and what they were good for. However, that meant that I had no idea what kind of academic subtradition my work could reasonably be situated into, and I wanted to have a good sense of where my research actually fit before I started writing. I suspect that an important part of academic communication is getting the correct people to see your work, so I thought it might be good practice to start to get into the habit of trying to identify those people. Knowing who you’re talking to helps you decide what kind of language to use.
For example, when I was working on the project, I read a lot of theoretically inclined algorithms design literature, gave myself a crash course in approximation algorithms, and learned some (basic) stuff about combinatorial optimization and submodularity. The paper I was implementing was more on the theoretical side, and I learned a lot of math in order to try to acquire a foundational understanding of what I was working with. But it turned out that the best way to position my project is as applied algorithmic research, specifically as an experimental evaluation of algorithms, and if I were to write a real paper, I would probably need to heavily rely on that kind of research in my citations instead.5 So in writing my abstract, I tried to channel applied algorithmic research energy, not theoretical algorithms energy.
The conference guidelines
The conference guidelines6 stated that each submission should consist of a max 250 word abstract with the following sections:
-
Introduction and Objective: this section should provide context to the reader, an introduction to the topic and its importance, and a statement of the study objective, question, or hypothesis, whichever is appropriate.
-
Materials and Methods: this section should describe the approach/method used for answering the research question.
-
Results: this section should provide a clear, concise, and explicit summary of the key findings.
-
Conclusion and Significance/Implication: this section should provide the reader with the take-home message from the study and explain how it relates to the study objective.
Now, I don’t know about you, but I have never seen an abstract that was explicitly split into four (five? I’m going to think of it as five) sections like that, and I assumed they weren’t looking for the abstract submissions to be explicitly broken up with those subtitles either. In an attempt to figure out whether real abstracts also follow this kind of structure, I assigned a colour (see above) to each of the attributes that the conference organizers said to include in the submitted abstracts. Then I tried to identify each section in a real abstract and highlight it. At the end, it gave me a better understanding of how abstracts are actually constructed and how much of each type of information they contain.
Based on that understanding, I then attempted to write my own abstract.
The abstracts I analyzed
Performance analysis of various machine learning algorithms for CO2 leak prediction and characterization in geo-sequestration injection wells [1]
Authors: Saeed Harati, Sina Rezaei Gomari, Mohammad Azizur Rahman, Rashid Hassan, Ibrahim Hassan, Ahmad K. Sleiti, Matthew Hamilton
The effective detection and prevention of CO2 leakage in active injection wells are paramount for safe carbon capture and storage (CCS) initiatives. This study assesses five fundamental machine learning algorithms, namely, Support Vector Regression (SVR), K-Nearest Neighbor Regression (KNNR), Decision Tree Regression (DTR), Random Forest Regression (RFR), and Artificial Neural Network (ANN), for use in developing a robust data-driven model to predict potential CO2 leakage incidents in injection wells. Leveraging wellhead and bottom-hole pressure and temperature data, the models aim to simultaneously predict the location and size of leaks. A representative dataset simulating various leak scenarios in a saline aquifer reservoir was utilized. The findings reveal crucial insights into the relationships between the variables considered and leakage characteristics. With its positive linear correlation with depth of leak, wellhead pressure could be a pivotal indicator of leak location, while the negative linear relationship with well bottom-hole pressure demonstrated the strongest association with leak size. Among the predictive models examined, the highest prediction accuracy was achieved by the KNNR model for both leak localization and sizing. This model displayed exceptional sensitivity to leak size, and was able to identify leak magnitudes representing as little as 0.0158% of the total main flow with relatively high levels of accuracy. Nonetheless, the study underscored that accurate leak sizing posed a greater challenge for the models compared to leak localization. Overall, the findings obtained can provide valuable insights into the development of efficient data-driven well-bore leak detection systems.
Statistics
- Publication venue: Process Safety and Environmental Protection, Volume 183, March 2024
- Publication type: Journal Article
- Subfield (best guess): Machine Learning/Petroleum Engineering
- Overall abstract length: 10 sentences, 242 words
- Introduction section: 1 sentence (10% of sentence count), 22 words (9.1% of word count)
- Objectives section: 2 sentences (20% of sentence count), 67 words (27.7% of word count)
- Materials and Methods section: 1 sentence (10% of sentence count), 14 words (5.8% of word count)
- Results section: 4 sentences (40% of sentence count), 102 words (42.1% of word count)
- Conclusion and Significance section: 2 sentences (20% of sentence count), 37 words (15.3% of word count)
Thoughts
I like this abstract. It is clear and to the point, and it seems to be the closest I’ve seen to that aspirational “sum up each of your sections in 1-2 sentences” advice. It is on the longer side – in fact, it’s the longest of the abstracts I’ve looked at here, but I do kinda think it has earned its length. Not much of it really feels superfluous.
I really hesitated about whether to consider the third sentence part of the objectives section or part of the materials and methods section. Really, the first half seems to be more about the method, and the second half seems to be more about the method, but it’s kinda fuzzy and I didn’t really feel like complicating my analysis.
I will say that the results section feels a little too long, and the methods section feels like it could use a little bit more information. Word count–wise, the materials and methods comprise about 6% of the word count, and the results comprise about 43% of the word count, being respectively the shortest and longest sections. I feel like maybe 10% to 38% (ish) would be a better split.
Comparative Study of Two Clustering Algorithms: Performance Analysis of a New Algorithm Against the Evidential C-Means Algorithm [2]
Authors: Yissam Lakhdar, Khawla El Bendadi
Clustering techniques are essential elements for exploring and analyzing data. This paper provides a comparative study between a new clustering algorithm based on a new density peak detection approach introducing the imprecise data concept, named Robust density peak detection with imprecision data (RDPTI), and the Evidential C-Means method. The aim of this research is to analyze the performance, efficiency and usefulness of the new algorithm against the established Evidential C-Means method. Unsupervised statistical classification methods based on probability density function estimation have a wide field of application. In this paper, we propose a new algorithm based on density peaks. By introducing the notion of imprecise data and combining two noise detection methods, this proposed algorithm produces three types of clusters: singleton clusters, meta-clusters and outlier cluster. In order to demonstrate the effectiveness and robustness of the RDPTI method, artificial and real data are tested and the algorithm is compared with the Evidential C-means algorithm, which is a clustering algorithm based on the belief function theory. Experimental results show that the proposed algorithm RDPTI improves clustering accuracy over the Evidential C-Means method. The outcomes provide precious information for scientists looking to take advantage of new clustering techniques for a variety of applications in data analysis.
Statistics
- Publication venue: Information Systems and Technological Advances for Sustainable Development: Proceedings of the Fifth International Conference (DATA 2024)
- Publication type: Conference Paper
- Subfield (best guess): Machine Learning, possibly?
- Overall abstract length: 9 sentences, 204 words
- Introduction section: 2 sentences (22.2% of sentence count), 26 words (12.7% of word count)
- Objectives section: 3 sentences (33.3% of sentence count), 73 words (35.8% of word count)
- Materials and Methods section: 1 sentence (11.1% of sentence count), 39 words (19.1% of word count)
- Results section: 2 (1 + 1) sentences (22.2% of sentence count), 43 words (21.1% of word count)
- Conclusion and Significance section: 1 sentence (11.1% of sentence count), 23 words (11.3% of word count)
Thoughts
This paper has the weirdest structure we’ve seen so far, flipping back and forth between introduction and objectives, then between results and methods. I think this comes from the fact that it seems like the paper actually has two main ideas in it:
- Proposing a new clustering algorithm
- Comparing the new algorithm against an established clustering algorithm.
Now, I don’t actually know anything about this field, so I don’t know if this is commonly how new algorithms are introduced in papers, but I feel like either this should have been two papers, or the abstract should have been framed differently, because right now it is structured like two different abstracts interwoven with each order, and the reading experience is mildly stilted as a result.
But then again, this did get published, and I probably wouldn’t have noticed this if it weren’t for the highlighting exercise. So what do I know?
Performance Analysis of Two Famous Cryptographic Algorithms on Mixed Data [3]
Authors: Emmanuel Abidemi Adeniyi, Agbotiname Lucky Imoize, Joseph Bamidele Awotunde, Cheng-Chi Lee, Peace Falola, Rasheed Gbenga Jimoh, Sunday Adeola Ajagbe
The rapid development of digital data sharing has made information security a crucial concern in data communication. The information security system heavily relies on encryption methods. These algorithms employ strategies to increase data secrecy and privacy by obscuring the information, which only those parties who have the accompanying key can decode or decrypt. Nevertheless, these methods also use a lot of computational resources, including battery life, memory, and CPU time. So, to determine the optimal algorithm to utilize moving forward, it is necessary to assess the performance of various cryptographic algorithms. Therefore, this study evaluates two well-known cryptographies (RSA and ElGamal) using mixed data such as binary, text, and image files. CPU internal clock was used to obtain the time complexity used by both algorithms during encryption and decryption. The algorithms used CPU internal memory to obtain memory usage during the encryption and decryption of mixed data. Evaluation criteria such as encryption time, decryption time, and throughput were used to compare these encryption algorithms. The response time, confidentiality, bandwidth, and integrity are all factors in the cryptography approach. The results revealed that RSA is a time-efficient and resourceful model, while the ElGamal algorithm is a memory-efficient and resourceful model.
Statistics
- Publication venue: Journal of Computer Science, Volume 19, No. 6, 2023
- Publication type: Journal Article
- Subfield (best guess): Cryptology
- Overall abstract length: 11 sentences, 199 words
- Introduction section: 5 sentences (45.4% of sentence count), 91 words (45.7% of word count)
- Objectives section: 1 sentence (9.1% of sentence count), 20 words (10.0% of word count)
- Materials and Methods section: 4 sentences (36.4% of sentence count), 67 words (33.7% of word count)
- Results section: 1 sentence (9.1% of sentence count), 21 words (10.6% of word count)
- Conclusion and Significance section: 0 sentences (0% of sentence count), 0 words (0% of word count)
Thoughts
This abstract has the longest introduction section of all of the abstracts I looked at, taking up about half of the abstract regardless of whether you count by words or sentences. I think it’s a very bizarre choice to spend half of an abstract, which is meant to summarize new research, telling the reader things they should already know. I am also really not a fan of the results section, which in my opinion lacks detail and specificity, especially considering the length of the abstract.
I don’t really know anything about research, but this abstract feels very poorly structured to me. It just feels like the emphasis and detail is placed in all of the wrong places, and the structure feels very unideal.
Quantum advantage with shallow circuits [4, 5]
Authors: Sergey Bravyi, David Gosset, Robert König
Preprint [4]
We prove that constant-depth quantum circuits are more powerful than their classical counterparts. To this end we introduce a non-oracular version of the Bernstein-Vazirani problem which we call the 2D Hidden Linear Function problem. An instance of the problem is specified by a quadratic form q that maps n-bit strings to integers modulo four. The goal is to identify a linear boolean function which describes the action of q on a certain subset of n-bit strings. We prove that any classical probabilistic circuit composed of bounded fan-in gates that solves the 2D Hidden Linear Function problem with high probability must have depth logarithmic in n. In contrast, we show that this problem can be solved with certainty by a constant-depth quantum circuit composed of one- and two-qubit gates acting locally on a two-dimensional grid.
Statistics (preprint)
- Publication type: Preprint
- Subfield (best guess): Quantum computing
- Overall abstract length: 6 sentences, 134 words
- Introduction section: 0 sentences (0% of sentence count), 0 words (0% of word count)
- Objectives section: 1 sentence (16.7% of sentence count), 13 words (9.7% of word count)
- Materials and Methods section: 3 sentences (50% of sentence count), 63 words (47.0% of word count)
- Results section: 2 sentences (33.3% of sentence count), 58 words (43.3% of word count)
- Conclusion and Significance section: 0 sentences (0% of sentence count), 0 words (0% of word count)
Final Publication [5]
Quantum effects can enhance information-processing capabilities and speed up the solution of certain computational problems. Whether a quantum advantage can be rigorously proven in some setting or demonstrated experimentally using near-term devices is the subject of active debate. We show that parallel quantum algorithms running in a constant time period are strictly more powerful than their classical counterparts; they are provably better at solving certain linear algebra problems associated with binary quadratic forms. Our work gives an unconditional proof of a computational quantum advantage and simultaneously pinpoints its origin: It is a consequence of quantum nonlocality. The proposed quantum algorithm is a suitable candidate for near-future experimental realizations, as it requires only constant-depth quantum circuits with nearest-neighbor gates on a two-dimensional grid of qubits (quantum bits).
Statistics (final publication)
- Publication venue: Science, Vol. 362, No. 6412 (Oct 2018)
- Publication type: Journal Article
- Subfield (best guess): Quantum computing
- Overall abstract length: 5 sentences, 126 words
- Introduction section: 2 sentences (40% of sentence count), 38 words (30.2% of word count)
- Objectives section: 0.5 sentences (10% of sentence count), 20 words (15.9% of word count)
- Materials and Methods section: 0.5 sentences (10% of sentence count), 6 words (4.8% of word count)
- Results section: 1 (0.5 + 0.5) sentence (20% of sentence count), 32 words (25.4% of word count)
- Conclusion and Significance section: 1 sentence (20% of sentence count), 30 words (23.8% of word count)
Thoughts (on differences and similarities between the versions)
This format of highlighting works really poorly for math, wow. It strikes me as much more appropriate for experimental sciences, since I’m not entirely sure what the “method” part is supposed to be. Calling what I highlighted in the final abstract part of the “materials and methods” is very much a stretch – it’s a math paper, of course they wrote a proof. This is literally the equivalent of an experimental scientist telling you that they did an experiment with no other details.
The final abstract is about the same length as the preprint abstract (are abstracts generally just shorter in math?), but a lot more balanced in terms of section types included, at the cost of the loss of details and specificity. For example, the preprint abstract gives a lot more details about how the proof was done and what the results actually were. The final abstract gives no details but does spend a lot more time contextualizing the result, which the preprint doesn’t do. The final paper was published In Science though, which isn’t a specialized journal, so maybe that’s why the final abstract gives so few technical details.
Actually, I’m going to make a wild guess here and claim that the two abstracts are written for entirely different audiences. Most mathematicians read papers on ArXiv, so I’m assuming most of the people who actually read the paper looked at the preprint version, not the final version. I did an entire project on this paper, and I never once looked at the final version of the abstract. This is probably good, since the preprint abstract was a lot more useful for my purposes. I think the preprint abstract was written to be read by mathematicians and other people in the field.
I think the final version was meant to be read by a much wider, very broad audience that might include non-scientists such as journalists. Science refers to itself as “a leading outlet for scientific news, commentary, and cutting-edge research” with “an estimated worldwide readership of more than one million.” That is massive for an academic journal. Also, consider this quote from the Science website:
“Science seeks to publish those papers that are most influential in their fields or across fields and that will significantly advance scientific understanding. Selected papers should present novel and broadly important data, syntheses, or concepts. They should merit recognition by the wider scientific community and general public provided by publication in Science, beyond that provided by specialty journals.”
I guess this right here is a prime example of “tailor your message to your audience”. I bet 99% of the Science readers look at the abstracts of the research papers and don’t even bother to attempt to read the rest. Members of the public aren’t going to care if half of the abstract is about “2D Hidden Linear Function problems”, whatever those are.
Opinion Dynamics on Discourse Sheaves [6, 7]
Authors: Jakob Hansen, Robert Ghrist
Preprint [6]
We introduce a novel class of Laplacians and diffusion dynamics on discourse sheaves as a model for network dynamics, with application to opinion dynamics on social networks. These sheaves are algebraic data structures tethered to a network (or more general space) that can represent various modes of communication, including selective opinion modulation and lying. After introducing the sheaf model, we develop a sheaf Laplacian in this context and show how to evolve both opinions and communications with diffusion dynamics over the network. Issues of controllability, reachability, bounded confidence, and harmonic extension are addressed using this framework.
Statistics (preprint)
- Publication type: Preprint
- Subfield (best guess):
- Overall abstract length: 4 sentences, 96 words
- Introduction section: 1 sentence (25% of sentence count), 27 words (28.1% of word count)
- Objectives section: 1 sentence (25% of sentence count), 27 words (28.1% of word count)
- Materials and Methods section: 0.5 sentences (% of sentence count), 14 words (14.6% of word count)
- Results section: 0.5 sentences (% of sentence count), 14 words (14.6% of word count)
- Conclusion and Significance section: 1 sentences (25% of sentence count), 14 words (14.6% of word count)
Final Publication [7]
We introduce a novel class of network structures called discourse sheaves, together with generalizations of graph Laplacians and diffusion dynamics, in order to model dynamics on networks with application to opinion dynamics on social networks. Such sheaves are algebraic structures tethered to a network that can represent various modes of communication, including selective opinion expression and lying. After introducing the discourse sheaf model for communication in a social network, we develop a sheaf Laplacian in this context and show how to evolve both opinions and communications with diffusion dynamics over the network. Issues of controllability, reachability, bounded confidence, and harmonic extension are addressed using this framework, providing a rich class of analyzable examples.
Statistics (final publication)
- Publication venue: SIAM Journal on Applied Mathematics, Vol. 81, Iss. 5 (2021)
- Publication type: Journal Article
- Subfield (best guess):
- Overall abstract length: 4 sentences, 113 words
- Introduction section: 1 sentence (25% of sentence count), 22 words (19.5% of word count)
- Objectives section: 1 sentence (25% of sentence count), 35 words (31.0% of word count)
- Materials and Methods section: 0.5 sentences (12.5% of sentence count), 21 words (18.6% of word count)
- Results section: 0.5 sentences (12.5% of sentence count), 14 words (12.4% of word count)
- Conclusion and Significance section: 1 sentence (25% of sentence count), 21 words (18.6% of word count)
Thoughts (on differences and similarities between the versions)
Honestly, these are pretty similar. The final version is just more cleaner up and has a bit more detail.
I think this is a great example of a short abstract that is well-rounded, easy to understand, and complete. Actually, I think this entire paper is the gold standard for math communication. It’s deep and complex math I know nothing about, but the authors lay it out in such a clear and organized manner that I can almost stumble through following it if I put in a lot of work. This is a miracle, considering that it involves algebraic geometry (highly simplified, but still).
Seriously, this is my favourite math paper.
Two Criteria for Performance Analysis of Optimization Algorithms [8]
Authors: Yunpeng Jing, HaiLin Liu, Qunfeng Liu
Performance analysis is crucial in optimization research, especially when addressing black-box problems through nature-inspired algorithms. Current practices often rely heavily on statistical methods, which can lead to various logical paradoxes. To address this challenge, this paper introduces two criteria to ensure that performance analysis is unaffected by irrelevant factors. The first is the isomorphism criterion, which asserts that performance evaluation should remain unaffected by the modeling approach. The second is the IIA criterion, stating that comparisons between two algorithms should not be influenced by irrelevant third-party algorithms. Additionally, we conduct a comprehensive examination of the underlying causes of these paradoxes, identify conditions for checking the criteria, and propose ideas to tackle these issues. The criteria presented offer a framework for researchers to critically assess the performance metrics or ranking methods, ultimately aiming to enhance the rigor of evaluation metrics and ranking methods.
Statistics
- Publication type: Preprint
- Subfield (best guess): Optimization - Performance Analysis
- Overall abstract length: 7 sentences, 142 words
- Introduction section: 2 sentences (28.6% of sentence count), 30 words (21.1% of word count)
- Objectives section: 2 (1 + 1) sentences (28.6% of sentence count), 45 words (31.7% of word count)
- Materials and Methods section: 0 sentences (0% of sentence count), 0 words (0% of word count)
- Results section: 2 sentences (28.6% of sentence count), 38 words (26.8% of word count)
- Conclusion and Significance section: 1 sentence (14.3% of sentence count), 29 words (20.4% of word count)
Thoughts
This abstract is also weird, and again, I don’t quite feel like the section descriptions fit here. It doesn’t seem like the authors are presenting experimental results here; rather, they are building some kind of theory or framework, which is why I didn’t really highlight a materials and methods section. But then again, what I’ve highlighted as the “results” section doesn’t really consist of results either.
To be fair, it is a preprint, so maybe the structure of this abstract will change upon publication. However, I suspect the main issue here is that the analysis method I’ve been using so far is ill-suited for this kind of paper and completely falls apart as a result.
Overall observations
Because this isn’t a random sample of abstracts from the same field, I think it’s absolutely useless to give metrics on the absolute word counts and sentence counts of the abstracts. I am going to give some relative metrics on the abstracts of the published papers – that is, I’m going to be excluding data from the preprints, which are mostly outliers anyway. The sample size here is five, so any generalized claims I make should be taken with a lot of skepticism.
Alright, let’s look at some charts.
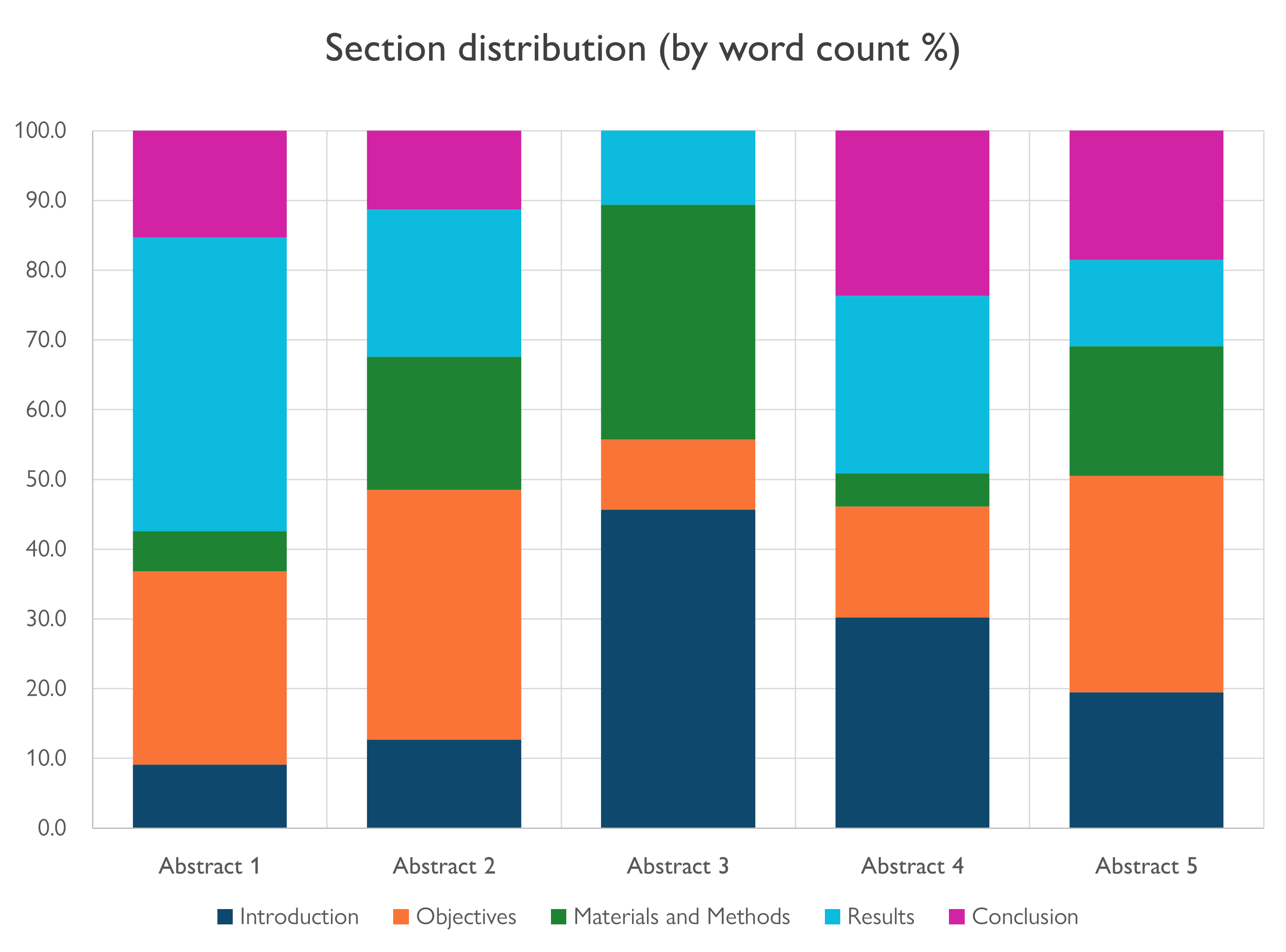
Section distribution, by word count
Here’s a more visual look at how much room each section took up in each of the abstracts. Looking at it this way is quite striking.
Sentences per section, by percentage
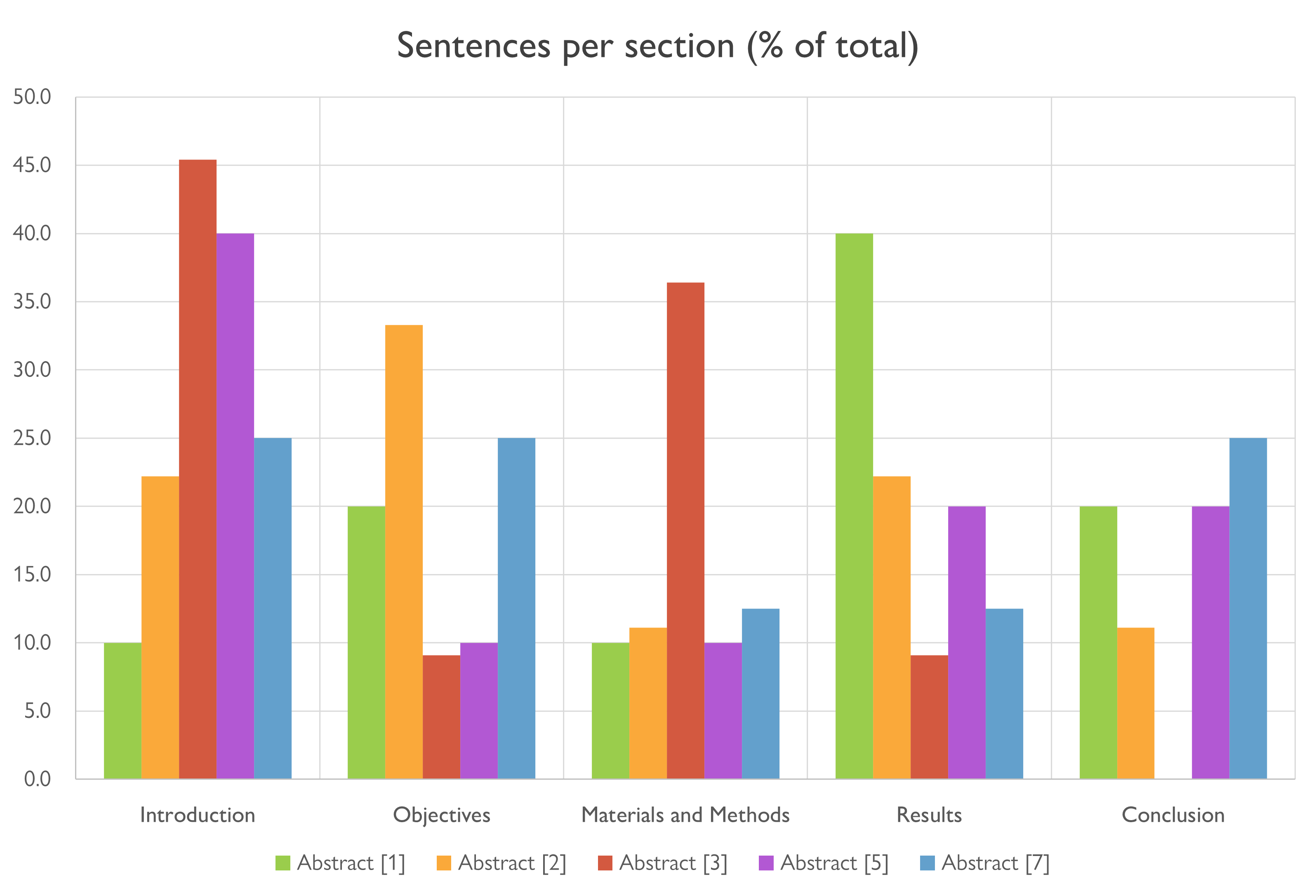
Turns out sentence count by percentage is an absolutely terrible metric. There is almost no consistency, since the abstracts have lowish numbers of sentences, so any variation in sentence count would cause wild swings in the percentages. If there was any sort of pattern, we would see the tops of the bars hovering at around the same levels.
Actually, maybe there is a pattern in the Materials and Methods section, but that’s probably just a coincidence.
Absolute sentence count per section
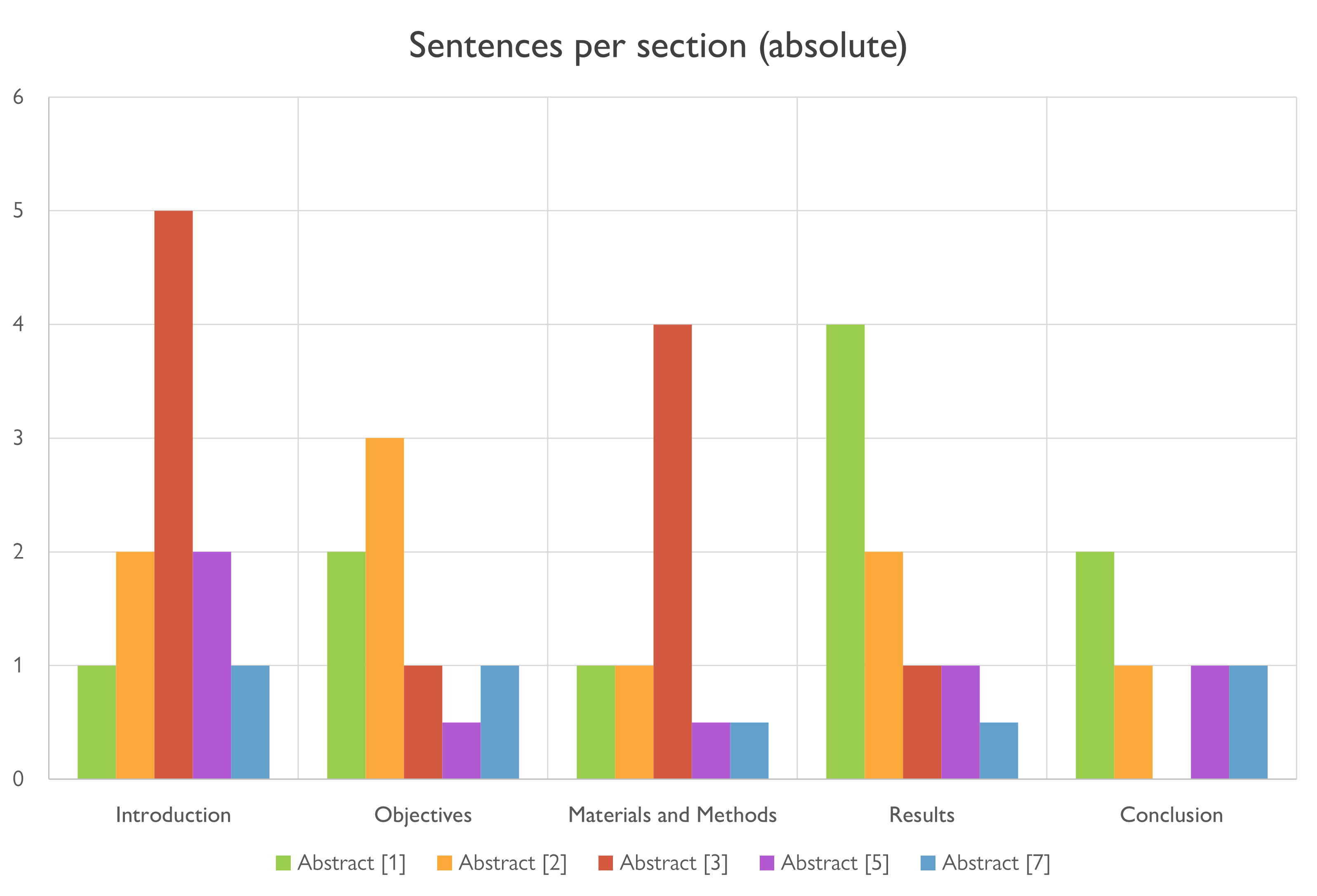
This seems like a much more coherent metric. I suspect that if I had a much bigger sample size I would see some patterns here. Maybe future me will do more of this kind of analysis.
Words per section, by percentage
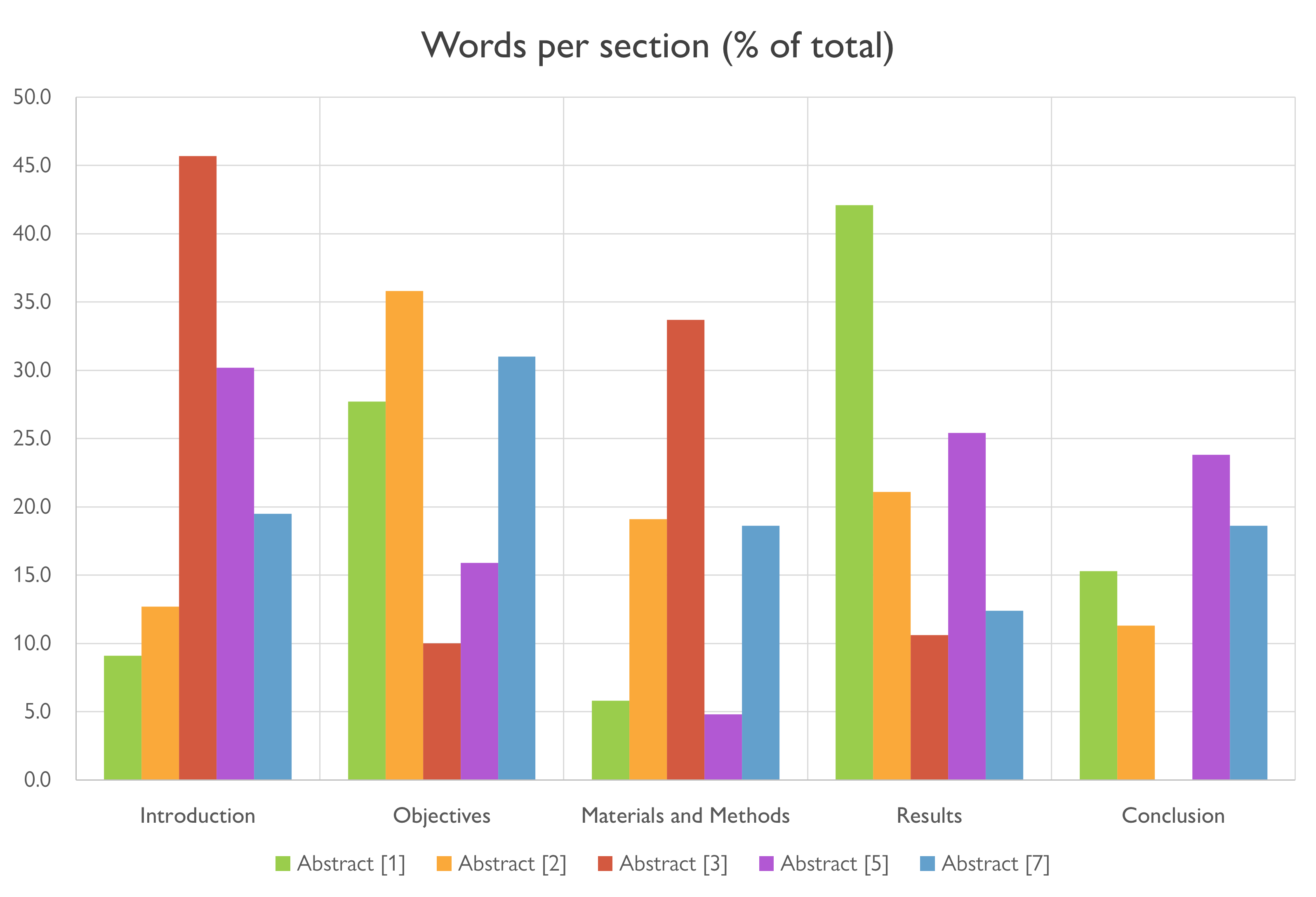
Apparently word count by percentage isn’t a very useful metric either. It is absolutely all over the place. I think what is really going on here is that there isn’t enough data to see any real kinds of patterns emerge.
Final thoughts
This was a very fun exercise, and I learned a lot from doing it. Really, the qualitative analysis was the most useful part, in that it directly helped me write an abstract that I hope sounded scientific enough to pass as real research. The qualitative analysis … well, that was for fun, out of curiosity. I really, really want to get back to doing it eventually, but properly with a lot more abstracts.
It sounds like it would probably be way too time-consuming, though. Oh, well.
-
Okay, maybe this is a lie. I didn’t do the qualitative analysis for fun. But the (very dubious and sketchy) quantitative analysis part of this article was 100% done for fun, out of curiosity, and now I’m wondering if anyone has actually done research on this. ↩︎
-
In case you were wondering, no, I did not end up presenting. But submitting was still a good exercise, I think. ↩︎
-
See, one fun thing about academic writing is that no one bothers to explicitly teach you how to do it, so you end up having to figure it out yourself through trial and error and osmosis and imitation. I guess this is also just called “being an adult,” but honestly, I don’t always feel like I’m smart enough to be an academic adult half the time. ↩︎
-
I’m pretty sure I have been told on one or two occasions that writing an abstract is just condensing every section of your paper into 1-2 sentences and putting them together, which is probably great advice under normal circumstances, but I didn’t actually have a paper written yet, so that wasn’t particularly useful to me. So not all of the advice I’ve received has been vague… just, you know, most of it. ↩︎
-
I think I totally underestimated how important lit reviews are last year, because I didn’t have any background or training in experiment design. (I’m a theoretically inclined CS major whose main other interests are in math and English… not a ton of experiment design to be found there.) I also had no idea what I was doing or where to look. However, now that I’d working on my undergrad thesis, which is much more experimental in nature, my supervisor has been getting me to read various papers that do similar types of experiments I can understand their methodology. I feel like it would have been really helpful for me to know to do this earlier. Oh, well. You can’t learn everything in the span of a single project. ↩︎
-
Wait, this is actually really helpful… thank you to these conference organizers for inadvertently writing the best guide to abstract writing that I’ve seen so far. ↩︎