Understanding the Python Memory Model
One of my quests this summer was to find a reasonably simple way to simulate pointers in Python, or at the very least, get some sort of named reference-like behaviour from the language. Unfortunately, I quickly learned that this is quasi-impossible, because Python is a language that aims to abstract as many implementation details away from the user as possible, and gives programmers very limited ways in which to interact with the language. (This is why you will often hear comments about doing things the “Python way”.) Python is not particularly concerned with speed; it is a language optimized for usability and simplicity, which means that doing anything complex at the low-level in Python can be a deeply frustrating experience.
There is pretty much no way for a programmer to directly access memory in Python; the language manages memory using the “private heap”, which is completely hidden from the programmer. In fact, unlike in most sane programming languages, variable names in Python do not point directly to memory locations. Instead, in Python we have names (variable names) and objects (values), and each time a value is assigned to a variable, what actually happens is that a name is bound to an object. Everything in Python is an object: ints, floats, dicts, lists, etc. are all objects, and they all behave in similar ways. The main distinction that causes differences in behaviours is that some objects are mutable, whereas others are immutable.
Every object in Python has three attributes: a type (e.g. string, int, bool), a value, and a reference count. (You can likely start to see how everything being an object means Python is pretty memory inefficient.) When a new variable is created and a value is assigned to it, what actually happens is the following:
- Python creates a new name.
- Python checks whether an object with that value already exists. If the object does not exist, it creates the object, sets its reference count to 1, and binds the name to that object.
- If there is already an object with that value, Python binds the name to that object, and increments its reference count by 1.
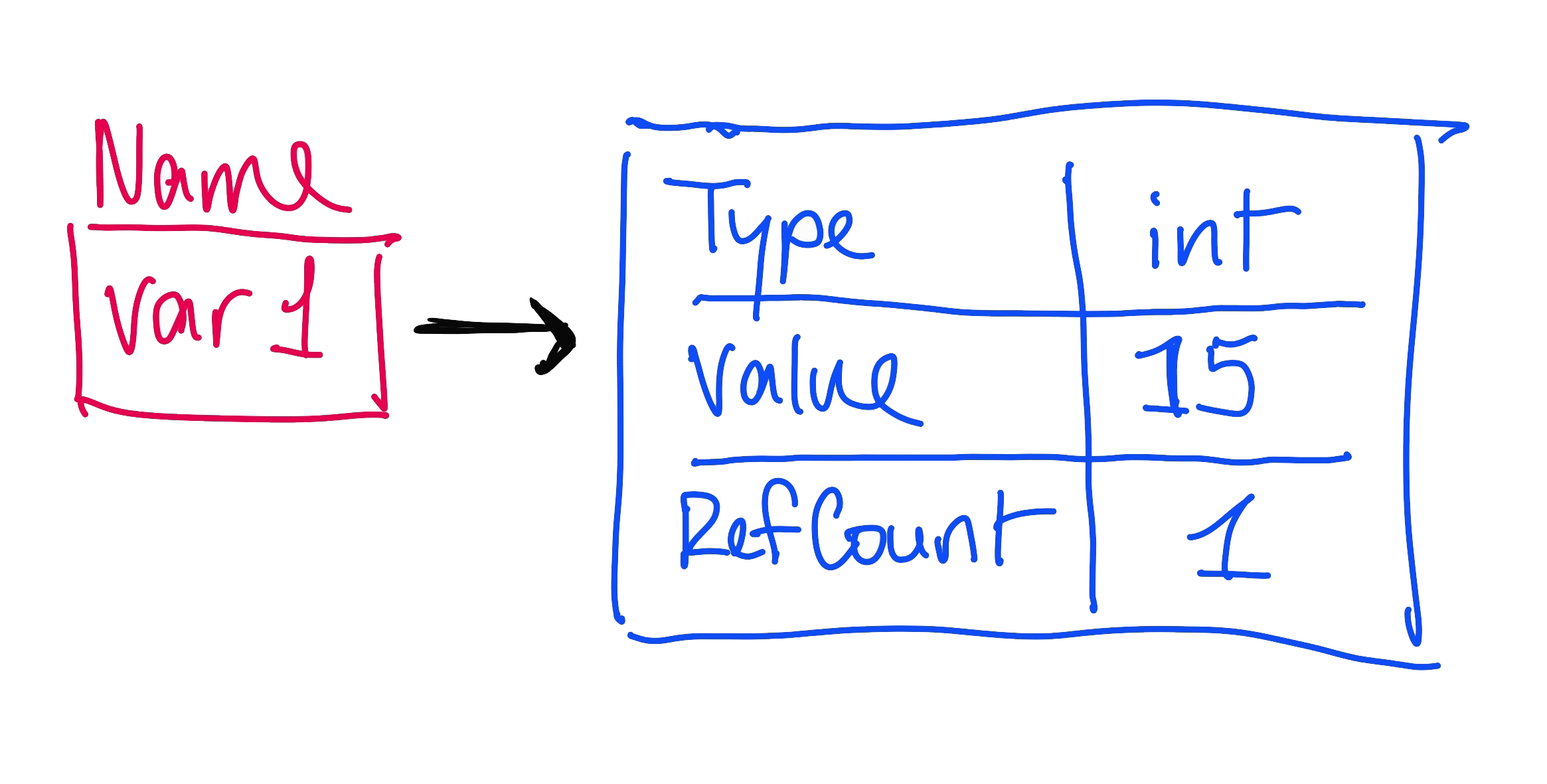
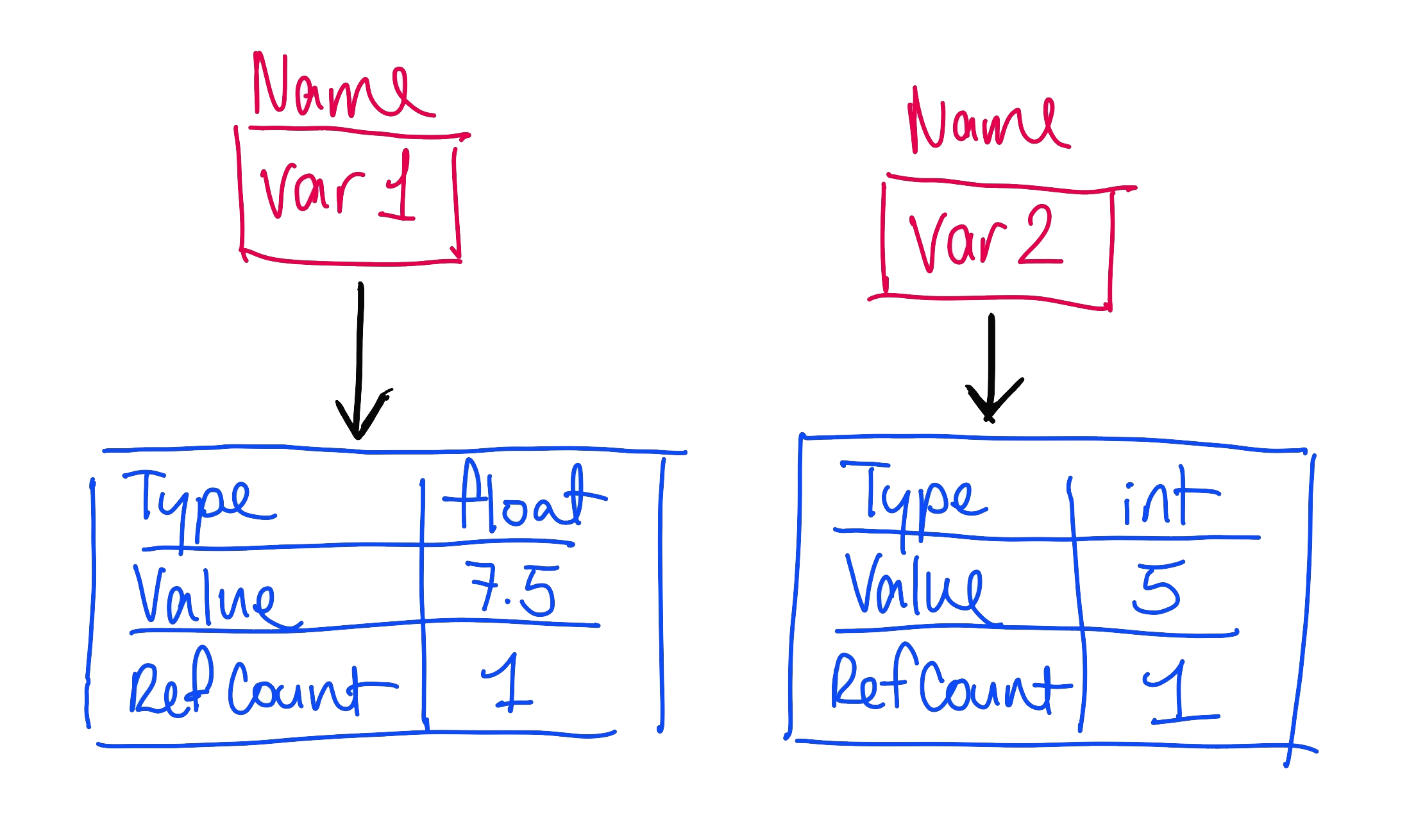
Now, let’s illustrate this scenario a little bit. Let’s say we have a variable, var1, which we want to set to the value 15. Python creates a new object with a reference count of 1.
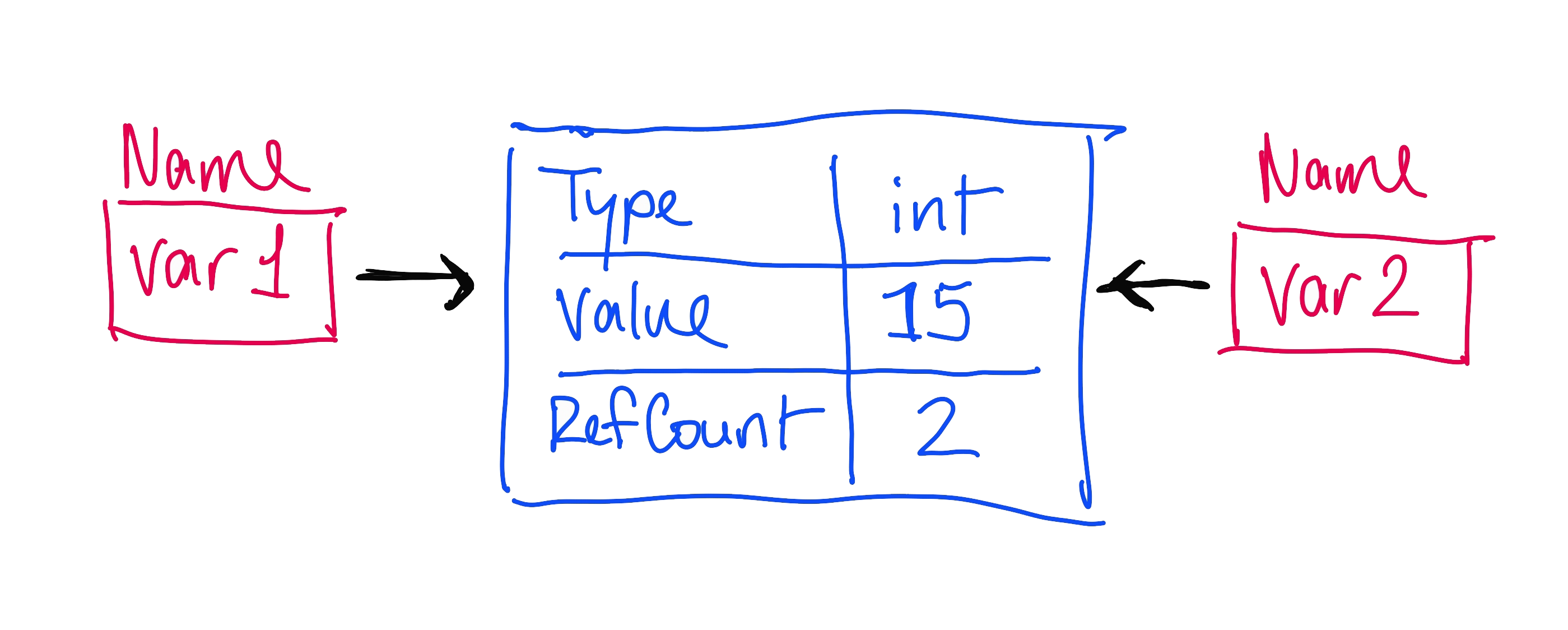
If we create a new object var2 and also set it to 15, then we increment the reference count of this object to 2.
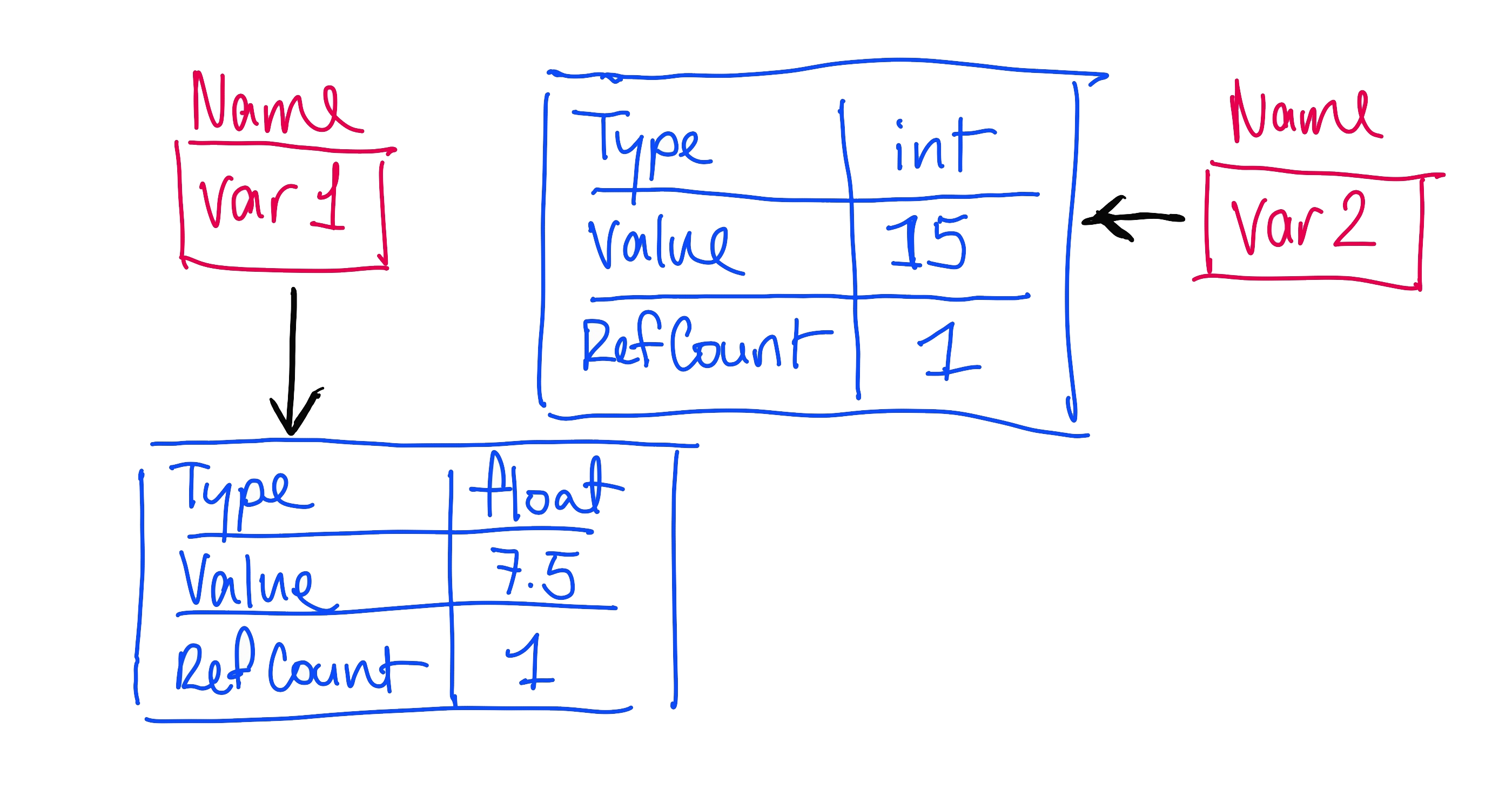
Here’s where things start to get weird: if we set var1 to itself divided by 2, Python doesn’t modify the original object, because integers are an immutable type in Python. Instead, Python creates a new object of type float, sets its value to 7.5, and sets its reference count to 1, while decrementing the reference count of the previous object. However, if var1 was a list, or some other mutable type, and we modified it, then both var1 and var2 would see the change.
Now, we set the variable var2 to its current value divided by 3. A new object with reference count 1 and the new value is created, the reference count of the first object we created is decremented to zero, and now, no names point to the original object.
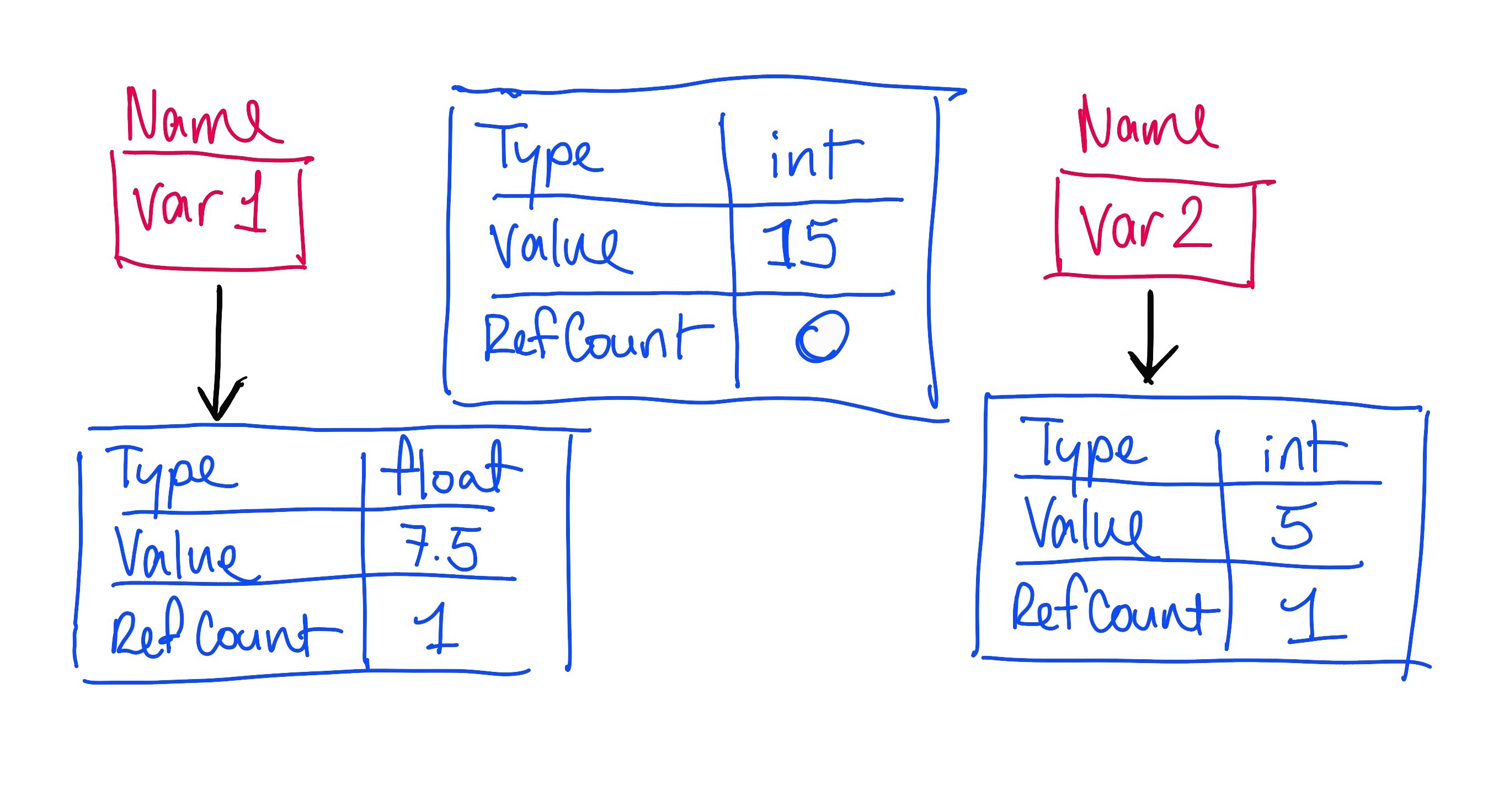
Once the reference count of an object hits zero, the Python garbage collector deletes it to recover the memory.
This might also explain some bizarre Python behaviours I have noticed. For example, when trying to create an empty 2-D list, instead of getting multiple empty lists inside the backing list, you get multiple pointers to the same empty list (which is almost certainly not what you want.) This is because Python is trying to minimize the total object count, and is doing so by creating multiple references to the same mutable object.
Python has a built in memory allocator that manages the allocation + deallocation of memory blocks. It optimizes for small objects by recycling previously allocated memory blocks to speed up future allocations (so, I assume that it doesn’t continuously deallocate and reallocate them), and uses dynamic memory allocation for complex objects such as lists and objects. In fact, Python organizes memory into different “pools” according to the size of the objects it intends to store in said pools, in order to decrease the amount of memory wasted.
What is most important to note here, however, is that the programmer has zero control over how this memory allocation happens, and so trying to write memory efficient code in Python is a both a nightmare and a waste of time. Go use C or Rust or something.
However, if for whatever reason, you do need to improve the memory efficiency of your Python code, there are two main tricks: one is using the __slots__ method in class definitions, and the other is using generators when processing large datasets. Both of these methods have limited utility in most contexts.
What the __slots__ method aims to do is let Python know exactly how many attributes each instance of the class is going to have, and create a “slot” for it ahead of time. This method is necessary because the default implementation of classes stores the attributes inside a dictionary, behind the scenes. While this allows the user to dynamically add new attributes to the class during code execution, dictionaries take up a lot more overhead than just having a few attributes. If it is not necessary to have the ability to dynamically add new class attributes, __slots__ should be used in order to save on memory. (Depending on the context, however, these memory savings may be functionally negligible.)
Generators allow Python to only hold one element of an iterable (such as a list) in memory at one time during processing, which can be helpful when working with very large datasets. However, note that this is only useful if you only need access to a single element at a time.
Further Reading/References